Глава 5. Реализация контекстно-зависимого управления
5.1. Неформальные требования
5.2. Инженерные проблемы проектирования
сложных систем
5.3. Компьютер фон Неймановской
архитектуры в системах высоких уровней
сложности
5.4. Частотная оценка
5.5. Информационная устойчивость
Инженерия
интеллектуальных
систем
- Сотворенный “по образу и подобию”
- только в Гордыне своей
- может отойти от доступной ему
- цели и назначения Эталона.
- Значит Человек должен быть инженером
- во всех своих деяниях,
- на всем протяжении своего пути.
- И если для этого ему нужна наука –
- пусть она будет инструментальной,
- пусть пройдет путь
- от абстрагирования на моделях
- до инструментария, которым пользовался
- Инженер Открытого Мира.
- Долог путь сотворения инструмента,
- счастлив будет садовник,
- вырастивший этот плод.
Глава 5. Реализация контекстно-зависимого управления
5.1. Неформальные требования
Практический разработчик системы управления для реального объекта с реальным окружением всегда оказывается вовлеченным в противоречия между требованиями алгоритмизации процессов, исходящими от техники и математического аппарата, и неопределимости формальных характеристик, возникающей при учете практики функционирования реального объекта в составе реальных подсистем.
С точки зрения прикладной теории ИСУ, если объект управления превышает по уровню сложности алгоритмически описываемое построение третьего уровня, то попытка алгоритмизации его функционирования является попыткой управления открытой системой высокого уровня (чаще всего - уровня общественного института) с помощью замкнутой системы. Но необходимо признать, что для значительного числа практических объектов реальные проблемы управления есть проблемы управления открытыми контекстно-зависимыми системами.
Можно сделать завод-автомат по серийному производству техники любой сложности или взять пробу лунного грунта или осуществить взлет и посадку на автопилоте – и эти попытки практически осуществлены, ибо здесь, несмотря на исключительную техническую сложность, и управляемая и управляющая системы будут принадлежать к уровню, обеспечиваемому кибернетическими построениями.
Управлять же выпуском продукции, имеющей экспериментальный, т.е. принципиально неопределенный до ее выпуска характер, или создать устройство, могущее самостоятельно существовать в окружающем нас обыденном мире, отличающимся от “алгоритмизируемого мира Луны” – задачи на кибернетическом уровне невозможные, ибо в отличие от первых, алгоритмизируемых обстановок, вторые существуют в неизмеримо более системно-сложном внешнем мире.
Решения, которые здесь должны приниматься, относятся к так называемым непрограммируемым решениям: “...решения можно считать непрограммируемыми, если они являются или новыми, или решениями с нечетко выраженной структурой, или особо важными. В этом случае не существует готового метода решения проблемы либо потому, что сама проблема раньше не возникала, либо потому, что ее точная природа и структура чрезмерно сложны, либо потому, что проблема настолько важна, что она заслуживает специального рассмотрения в индивидуальном порядке” [19].
Без дополнительных уточнений ясно, что большинство реальных систем управления сложными объектами относятся к системам с непрограммируемыми решениями и, значит, попытки создания систем управления объектами высокого уровня сложности должны быть поддержаны возможностями адекватной теории для принятия лучшего решения из доступного подмножества возможных решений.
Вообще говоря, сложнейшая проблема выработки непрограммируемого решения на уровне интеллектуальных систем связана с многочисленными внутри и вне системными факторами, соответствующими в своих проявлениях уровню сложности конкретных систем. Сказанное необходимо учитывать при создании интеллектуальной базы. Это область неопределенности, где системы класса СУО, как правило, не в состоянии информировать как они пришли к определенному решению и какое решение будет воспринято их окружением как правильное. Часто еще труднее определить, было ли это решение правильным в контексте имеющейся информации и осталось ли таковым после его принятия.
Следующая проблема заключается в том, что последовательность действий и выводов, ведущая к принятию управляющих решений, чаще всего не являются одинаково приемлемой с точки зрения верхнего и нижнего уровня внутренней иерархии управляющих подсистем составляющих открытую систему. В связи с тем, что управление зависит от имеющейся информации, важнейшим вопросом информационного обеспечения является проблема понимания необходимой степени его полноты различными уровнями этой иерархии.
Обычное отношение в иерархии подсистем высокого уровня системной сложности складывается следующим образом: подсистемы некоторого конкретного уровня иерархии за счет уменьшения (искажения) информации стараются обеспечить себе достаточную свободу вариации своей деятельности, в то время как высший по отношению к ним уровень желает иметь информацию, достаточную для обеспечения своей независимости от отчетности низшего уровня.
Например, внешний уровень управления может считать целесообразным требовать сведения о внутренних информационных пересылках низшего уровня или желать знать не только о том, что сделано, но и как делалось. При этом он сам выступает как низший уровень по отношению к следующей иерархической ступени со всеми вытекающими последствиями.
Отсюда следует вывод: чтобы информация эффективно поставлялась между подсистемами, не встречая препятствий, необходимо учитывать интересы нижних уровней иерархии. Нужно помнить, что нижние уровни находятся в таком положении, что их локальные интересы могут частично не совпадать с глобальными интересами каждого следующего уровня{91. Здесь можно поставить вопрос исследования проблем информационной выживаемости или гомеокинетической устойчивости интеллектуальных систем различных уровней соподчинения в борьбе за получение и сокрытие информации. И не надо проецировать сказанное только на системы, образованные человеческим обществом. Разделение информации по ее доступности – один из важнейших моментов негэнтропийного информационного процесса.}.
Очевидно, что любая система имеет смысл только при передаче информации между ее подсистемами. Учет и эффективное преодоление указанного выше противоречия являются необходимым организационным фактором создания информационного обеспечения управления, одним из важнейших требований прикладной теории ИСУ.
В частности, это требование к специальным свойствам базы знания, структура которой должна учитывать различное отношение к значимости (адресной, а не абстрактной “семантической” ценности) одной и той же информации на уровне различных подсистем.
5.2. Инженерные проблемы проектирования сложных систем
Публикации по теории создания управляющих систем и практике их разработки для сложных в системном смысле объектов обычно ориентированы на построение кибернетической модели. В них сначала формулируется постановка задачи, в которой указываются некоторые существенные стороны объекта, подлежащего рассмотрению. Затем делается переход к анализу той или иной модели или множества моделей, причем вопрос об адекватности этих моделей поставленной задаче, как правило, обходится или сопровождается общими утверждениями о пригодности модели для отражения “существенных” свойств объекта.
Однако обратим внимание на эпиграф этого раздела. Мы не просто согласны с этим утверждением. Это прямое подтверждение и принятие теории систем по фон Берталанфи, это ясный и четкий вывод: практика показывает необходимость ориентации на работу с открытыми системами, по крайней мере, начиная с четвертого уровня информационной сложности.
По-видимому, наиболее объективно к этому вопросу подходит так называемое имитационное моделирование в его авторской постановке [14]. Из этой монографии со всей очевидностью следует, что автор, хотя и не использует терминологию уровней сложности, в конечном счете, неявно постулирует, что в основу имитационного моделирования положено предположение о не существовании конечной кибернетической модели (или конечного множества моделей) сложного объекта.
Для избавления от проблем постановочного уровня, имитационное моделирование самому автору пришлось объявить искусством, по крайней мере, в части построения и совершенствования моделей объектов. Именно таким образом в нем предлагается оставаться на почве формально обоснованных методик при разработке и реализации систем. Однако ясно, что такое “слишком общее” решение вопроса адекватности модели не позволяет в рамках имитационного моделирования получить ответы на многие вопросы как теоретического, так и практического свойства.
В излагаемом ниже материале нас будет интересовать постановка задач и поиск возможностей применения формально корректных методов и подходов в прикладной теории ИСУ для моделирования систем высоких уровней сложности или даже организации непосредственной работы с ними, исключая модель как обязательный атрибут восприятия системы, что как мы уже упоминали, не противоречит ОТС по фон Берталанфи.
Несколько экскурсов в различные разделы программирования и смежные области также являются “собственностью” прикладной теории ИСУ. В них нас будет интересовать существование подходов, позволяющих строить в компьютере или встраивать компьютер в системы, не представимые кибернетическими моделями.
Известно, что интерполяция постановки работ, ориентированной на реализацию конечно-автоматных моделей с большим числом параметров, на внешне похожие разработки для систем, изначально требующих ИСУ, приводит к печальным результатам. Рассмотрим какую-либо достаточно простую на первый взгляд систему, выполняющую функции управления, например функции управления учетом, применением и распределением материалов и комплектующих.
Напомним основные (далеко не все) требования к системам управления такого рода:
Указанные требования выглядят отнюдь не чрезмерными, даже скорее минимально необходимыми, но какими средствами возможно их реализовать?
К примеру, одной из проблем управления в таких системах является проблема эквивалентной замены материалов и комплектующих, вроде бы аналогичная проблеме замена рейса в соответствующей автоматизированной системе продажи билетов. Однако в течении года появляется до нескольких тысяч наименований комплектующих изделий и новых видов материалов, причем значительное их число либо вообще не имеет аналогов в прошлом, либо это аналоги отдаленные.
Таким образом, базы данных и знания должны практически перманентно находиться в состоянии обновления, иначе не удастся выполнить указанные выше требования. Ясно, что вариабельность систем типа резервирования билетов несравненно ниже.
В реальных гипертекстовых системах - классификаторах промышленного уровня и, например, библиотечных системах, где объекты классифицируются по специальным корректируемым алгоритмам, за правильность пополнения информационного фонда отвечают группы экспертов. Конкретное занесение информации на носители и ее структуризацию выполняют специалисты в области программирования.
И при всем этом оперативность пополнения справочных фондов оставляет желать лучшего даже на предприятиях ведущих отраслей. Внедрение классификатора ЕСКД в сколько-нибудь широких масштабах не удалось именно по этой причине.
Приведенные выше требования несовместимы по крайней мере на кибернетическом уровне: для того, чтобы гарантировать оперативность системы, мы обязаны либо потребовать от пользователей умения выполнять работу системщика, т.е. правильно сформировать взаимосвязь новой информации с уже имеющейся, либо включить в штат экспертов по системному анализу, либо существенно пожертвовать достоверностью справок, которые впоследствии выдаст система.
Можно, наконец, потребовать, чтобы система сама проявила достаточный уровень интеллекта, т.е. прекратить попытки работы на кибернетическом уровне и перейти к использованию, а в необходимых случаях – развитию прикладной теории ИСУ.
На практике ситуация, по мере ее изучения, становится все более сложной. Огромное количество материалов и высокая скорость обновления их номенклатуры привели к тому, что не только технологи, но и работники снабжения и другие пользователи начинают создавать свой упрощенный язык номенклатурных номеров и профессиональных сокращений, малопонятных друг другу и коллегам из смежных предприятий и областей знания.
Таким образом, в процессе формирования языка системы возникает еще и вопрос стыковки множества специализированных языков подсистем (т.е. проблема множества несовместимых баз), отражающих всевозможные аспекты описания составляющих подсистемы объектов.
К примеру, магнитная проницаемость новой марки стали может быть никогда не понадобится проектировщику зубчатых колес, но магнитные и термические параметры той же стали могут в совокупности оказаться решающими для разработчика магнитных муфт. Попытка обойти эту проблему, записывая в информационную базу все признаки материала, очевидно, приведет к такому справочнику, ни создать, ни поддерживать, ни пользоваться которым будет невозможно.
Следовательно, нас должен интересовать поиск возможности создания некоторых семантических конструкций на проблемно-ориентированном уровне, обеспечивающем не только конкретику одного направления деятельности, но и понимание указанных выше пользовательских диалектов специализированных языков подсистем. Иначе нам нужен один сверхуниверсальный ПОЯ, т.е. сам естественный язык человека во всей его полноте и контекстной зависимости.
Под семантическими конструкциями в данном контексте, прежде всего, необходимо понимать языки, менее жесткие в своих построениях, чем процедурные. Практически в нашем распоряжении имеются достижения функционального и логического или реляционного программирования. Все они обладают весьма ограниченными возможностями для обработки даже проблемно-ориентированных языков.
Кроме того, системы, построенные на базе языков программирования типа lisp и ему подобных, практически не поддаются диагностике. Иначе говоря, получая от такой системы не удовлетворяющие нас решения, мы не имеем гарантированной возможности заставить систему сообщить нам, почему, по какой причине и внутри какой из составляющих ее программ зародилась нежелательная ситуация.
Этот факт известен как проблема lisp-отладчика, т. е. проблема не существования алгоритма (способа) узнать, почему некоторая программа ведет себя именно таким образом, иначе как проделав в точности те же действия и в той же последовательности. Некоторые возможности решения этой проблемы предусматриваемые в lisp-подобных языках типа ML и Miranda ситуацию кардинально не изменяют.
Рассмотрение проблем, возникающих при проектировании систем управления, можно было бы продолжить, однако уже из приведенных примеров видно, что удовлетворение даже минимальных, но практически необходимых требований задания на проектирование вроде бы алгоритмизируемых действий, приводит к необходимости создания системы на уровне, качественно более сложном, чем третий.
Пример со справочником демонстрирует, на сколь низком, по принятым понятиям, уровне проявляется проблема, связанная с необходимостью создания интеллектуальных систем. Здесь она проявилась как проблема перехода рассмотрения системы с третьего уровня на уровень “общественного института” даже при, казалось бы, довольно скромных требованиях к ее возможностям.
Что же делают разработчики, ограничивающиеся третьим уровнем проектирования? Если проанализировать любую из известных систем такого рода автоматизации управления, то видно, что главным в реализациях, имеющих практическую ценность, является способность разработчиков удачно воспользоваться теми или иными возможностями упрощения представления функционирования объекта, т.е. свести его функции к системе третьего уровня.
При этом интеллектуальные задачи – установление связей между объектами с учетом некоторых неформальных и переменных во времени ограничений и семантический контроль информационной базы, полностью выносятся за рамки программного обеспечения и возлагаются на проблемного специалиста, которому в лучшем случае предоставляется формализованный на уровне процедурного языка инструмент для осуществления смысловой стороны деятельности.
В итоге указанные требования получают в каждом конкретном случае некоторое паллиативное решение, и задача считается разрешимой на уровне кибернетической модели. Практики хорошо знают, что время жизни таких решений весьма мало, ибо определяется соглашениями о формальных действиях сторон, которые чаще всего считаются пользователями системы необязательными, но, с другой стороны, строго обязательны для существования управляющей системы.
5.3. Компьютер фон Неймановской архитектуры в системах высоких уровней сложности
Прикладная теория ИСУ ставит вопрос о принципиальной возможности построения моделей, более сложных, чем кибернетические или, как это будет видно из дальнейшего - о возможности принципиального отказа в некоторых случаях от моделирования сложных систем и организации непосредственной работы с ними. Обсудим наиболее перспективные направления, а также выскажем предложения по решению этого вопроса на базе современных компьютеров и современного уровня развития формального аппарата. Тем самым, в какой-то мере, ответим на вопрос о перспективах прикладной теории ИСУ и возможных путях организации работы с системами высокого уровня сложности.
Прежде всего, обратим внимание на тривиальный факт конечности любого компьютера как по памяти, так и по быстродействию. Это, с одной стороны, практически означает, что математически корректно заданная задача не всегда может быть решена в своем функциональном описании, если последнее превосходит в своей вычислительной сложности определенные границы, а, с другой стороны, даже бесконечный рост вычислительных мощностей не дает никаких гарантий соответствующего повышения точности модельного представления (см. часть III).
С другой стороны, семиотическое, текстовое или любое другое нефункциональное описание также имеет свои пределы, причем они зачастую проявляются еще до исчерпания ресурсов памяти и быстродействия. В контексте ИСУ укажем на две возникающие здесь проблемные задачи.
Во-первых, это вычисление так называемой “функции расстановки” в информационной базе, под которой здесь мы понимаем способ указания взаимосвязей между ее элементами. Сказанное позволяет сформулировать одно из важнейших требований, предъявляемых прикладной теорией ИСУ к разработкам баз знания: разработка баз знания прикладного применения должна вести, в конечном счете, к созданию структур данных, обеспечивающих эффективное формирование и направленное изменение функции расстановки.
Функция расстановки - функция, введенная для исключения сплошного перебора при работе с информационными базами, трактуется здесь в более широком смысле характеристики внутренних связей в базе знания. Она будет еще обсуждаться как проблема структурного резонанса (см. часть III), а пока отметим, что проблема структур хранения обеспечивает значительную часть трудностей при реализации попыток постепенного повышения сложности обрабатывающих алгоритмов, которые обычно предпринимаются, когда профессиональному программисту начинает казаться, что можно заставить вычислительную машину делать все что угодно{92. Мы убедились на своем опыте, что популяризаторы программистских языков умудряются приводить в такое состояние и молодых специалистов еще на школьной скамье. Часть из них приходит в вуз с убеждением, что запрограммировать можно все и только “изначально заложенная в человека тяга к минимизации своей деятельности” удерживает их от таких попыток, но не от интуитивной веры в могущество операторов “и”, “или”, “не”, “если”. Не пора ли все учебники начинать с указания “чего не может” очередной язык программирования? Или всегда проще описать, что он может, а на все остальное никакого объема публикации не хватит?}. Именно в таких ситуациях система, созданная программистом, показывает, что у нее есть своя собственная жизнь и она определенно выходит из под контроля.
Во-вторых, это проблема создания языка для пользователя информационной системы, который должен удовлетворять двум принципиально противоречивым требованиям, частично указанным в предыдущем разделе.
С одной стороны, этот язык должен включать в себя возможность самоописания для обеспечения развития информационной системы до уровня переводчика профессиональных жаргонов. С другой стороны, программы, запросы, директивы пользователей должны быть всегда диагностируемы, так же как программы на языках процедурного типа. Иначе говоря, пользователь должен иметь возможность за конечное число попыток установить, что и каким образом делает его программа. Более того, учитывая требование автоматичности системы, желательно, чтобы некорректные программы вообще не исполнялись.
Возможное решение проблемы, рассматриваемое в прикладной теории ИСУ, состоит в следующем.
Теория в этой части направлена на установление формализованного понятия “правильно работающей конструкции”, а именно, конструкции, завершающей работу за конечное число шагов и только одним из заранее определенных способов.
Исходя из этого, в прикладной теории ИСУ предлагается концепция, базирующаяся на том, чтобы не решать проблему отладки, но обеспечивать корректность конструкций для задания знания. Ставится вопрос о разработке такого формального аппарата, чтобы сам акт записи информации стал одновременно и актом доказательства ее корректности (например, в пределах текущего значения функции расстановки или ее нового значения, порожденного этим актом).
Для этого возможно использовать формализм типа “преобразователя предикатов” - фактически некоторое подмножество языка исчисления предикатов, например, первого порядка, сформированное с учетом аксиом, определяемых конечностью памяти и быстродействия компьютера и оформленный как язык фиксации текущего знания. В известной степени такой язык может быть предложен и в качестве входного языка, и в качестве языка описания системы высокого уровня.
Отметим, что речь идет здесь о разработке программ и выражений в рамках аппарата исчисления предикатов, из которых состоит система и являющихся, в конечном счете, самой системой (по крайней мере до тех пор, пока она не получит другого описания, которое будет признано вместо предыдущего). Это, например, системы, реализующиеся как семантические конструкции. Для значительного числа систем представление на уровне исчисления предикатов первого порядка может быть достаточно для их адекватного восприятия{93. Не критикуйте нас за использование первого порядка. Кванторы являются не препятствием, но только усложнением построений, а у нас хватает сложности и по нашей основной тематике.}.
Если последовательно применять формализм “преобразователей предикатов”, то, построив сколь угодно разветвленную многоуровневую систему, мы получим механизм, опять являющийся “преобразователем предикатов”, то есть механизм, обладающий важными для нас свойствами: всегда правильно завершать работу и быть распознаваемым за конечное число шагов.
“Правильное завершение работы” означает, что конструкция (программа) за конечное время приходит либо к состоянию, являющемуся удовлетворительным с точки зрения логики системы решением, либо к состоянию “неопределенность” с выдачей диагностики о причине неопределенности. Излагаемая методология получила свое практическое решение в создании прикладного языка для работы с описательно заданными объектами (см. гл. 3), причем возможность ее использования в различных областях знания зависит только от наличия информационных массивов.
Совершенно очевидно, что такой язык “в чистом виде”, язык, построенный на базе “преобразователей предикатов”, язык с явным указанием локальных, глобальных и наследуемых переменных, областей действия переменных, с полным отказом от рекурсии и явной заменой ее на повторение, является языком того же уровня, что и, например, паскаль, т.е. контекстно-свободным языком. Некоторые аспекты проблемы сохранения в нем контекстной зависимости уже рассматривались. Посмотрим на них еще раз “с программистской точки зрения”.
5.4. Частотная оценка
Обратим внимание на следующие два обстоятельств, являющихся центральными для всех дальнейших рассуждений.
Во-первых, система типа информационно справочной для задач управления должна обладать интеллектуальными свойствами лишь на некоторых отрезках времени, в течение которых происходят модификации информационной базы (знания), что эквивалентно осознанию системой новой функции расстановки. В каждом акте общения пользователя с системой с целью получения информации структуризирующие интеллектуальные свойства системы не являются строго необходимыми.
Исходя из конкретной постановки задачи для системы или систем заданного типа, можно выделить отрезки времени статические, т.е. те, на которых система ничем не отличается от конечного автомата, и динамические, т.е. такие, на которых происходит реорганизация системы, в частности – реорганизация структуры интеллектуальной базы, переопределение информационных связей.
Во-вторых, если система реализована корректно на уровне программ и ее поведение конечно-распознаваемо, вовсе не обязательно, чтобы ее ответы были всегда безошибочны. Право на ошибку давно признано за интеллектуальными системами. Во всяком случае, абсолютная полнота и правильность ответов не должны следовать из постановки задач создания как простейшей информационно - справочной, так и интеллектуальной системы. И та и другая пользуются информацией от внешнего мира, которая может быть неопределенной или противоречивой и, кроме того, эти системы имеют логику своих решений, базирующуюся на конечном числе известных ситуаций.
Это означает, с одной стороны, что мы можем допустить появление ошибок в ответах с частотой, не превышающей некоторого заданного уровня. Частотная оценка используется здесь по существу задачи, ибо на любом конечном числе актов общения с системой мы имеем дело с конечным числом объектов (ситуаций) и конечной аппроксимацией функции расстановки, так что использование предельного перехода к статистическим оценкам по вероятности представляется здесь некорректным.
С другой стороны, по мере накопления информационной базы и работы с ней, вид функции расстановки по сути задачи создания высокоуровневой системы, по-видимому, должен изменяться столь существенно, что различные реализации ее, принадлежащие разным статическим интервалам, могут не принадлежать к одному рекурсивному множеству и эта принадлежность не может быть установлена никаким конечным алгоритмом.
В этом смысле в теории ИСУ приходится иметь дело с реализацией конечной аппроксимации функции расстановки, которая по существу не является рекурсивной, а может быть и рекурсивно-перечислимой (т.е. не является множеством значений некоторой рекурсивной функции).
Исходя из сказанного, можно предложить
следующую постановку задачи. На каждом интервале
времени существования информационной базы
имеется реализация функции расстановки в виде
частичного эффективного оператора Т,
представляющего собой n-ку частично-рекурсивных
функций ![]() от n
переменных, причем из n равенств
от n
переменных, причем из n равенств ![]() ,
, ![]() по
крайней мере m,
по
крайней мере m, ![]() истинны и
истинны и ![]() ,
, ![]() истинны только в том
случае, когда определены и левая и правая части
равенства и они равны. Вопрос о практической
осуществимости пополняемой и модифицируемой
информационной базы принимает в этом случае
следующий вид: существуют ли эффективные
реализации оператора Т в частотном смысле?
Ясно, что точная реализация оператора Т вовсе
не обязана быть эффективной. С другой стороны,
очевидно, что каждая конечная совокупность
объектов базы данных (т. е. после каждого акта
пополнения) рекурсивно-перечислима, но не
обязательно тем же способом, что и после
предыдущего пополнения.
истинны только в том
случае, когда определены и левая и правая части
равенства и они равны. Вопрос о практической
осуществимости пополняемой и модифицируемой
информационной базы принимает в этом случае
следующий вид: существуют ли эффективные
реализации оператора Т в частотном смысле?
Ясно, что точная реализация оператора Т вовсе
не обязана быть эффективной. С другой стороны,
очевидно, что каждая конечная совокупность
объектов базы данных (т. е. после каждого акта
пополнения) рекурсивно-перечислима, но не
обязательно тем же способом, что и после
предыдущего пополнения.
Приведенная формулировка соответствует постановке задачи о частотном решении проблемы вхождения в рекурсивно-перечислимое множество, предложенной в [25] и имеющей положительное решение при сформулированном ограничении – допущении некоторого уровня ошибок. Следовательно, проблема формально разрешима.
Итак, формально возможно построение абстрактных конструкций, реализующих невычислимые в обычном смысле объекты{94. Этот материал излагается на основе нашей работы [4], написанной еще в конце 70-х годов и опубликованной в 1982 г. Сегодня все больше ученых начинают говорить о “невычислимых сущностях” именно в той направленности, которая и была затронута в указанной работе.}. Далее, не входя в подробности теории частотных вычислений, сформулируем лишь окончательный результат относительно границ сложности формальных конструкций, реализующих интересующие нас объекты.
1. Для формальной конструкции S и
желательного послеусловия R назовем
слабейшим предусловием ![]() такое предусловие, что S, начиная
работу в
такое предусловие, что S, начиная
работу в ![]() , закончит
работу в состоянии, удовлетворяющем R; при
начальном состоянии, не удовлетворяющем R, S
завершает работу в непредсказуемом состоянии, в
том числе может не прийти к завершению
(зациклиться).
, закончит
работу в состоянии, удовлетворяющем R; при
начальном состоянии, не удовлетворяющем R, S
завершает работу в непредсказуемом состоянии, в
том числе может не прийти к завершению
(зациклиться).
2. Слабейшим свободным предусловием ![]() назовем такое
предусловие, начиная работу в котором, S
завершает работу одним из перечисленных ниже
способов. При этом для каждого из вариантов
завершения существует следующая характеризация
множества начальных состояний:
назовем такое
предусловие, начиная работу в котором, S
завершает работу одним из перечисленных ниже
способов. При этом для каждого из вариантов
завершения существует следующая характеризация
множества начальных состояний:
a) ![]() =
=![]()
т.е. S приходит к истинности R;
b) ![]()
т.е. S приходит к истинности ![]()
c) ![]() =
=![]()
т.е. S не приходит к правильному завершению;
d) ![]()
т.е. S приходит к завершению, но по начальному состоянию нельзя определить, будет ли завершение удовлетворять R;
e) ![]() &
&![]()
т.е. если система придет к конечному состоянию, то оно удовлетворяет R, однако завершимость не гарантируется начальным состоянием;
f) ![]()
т.е. если система придет к конечному
состоянию, то оно удовлетворяет ![]() , завершимость не гарантируется
начальным состоянием;
, завершимость не гарантируется
начальным состоянием;
g) ![]()
т.е. по начальному состоянию нельзя
определить, завершится ли работа S, а при
завершении – будет ли удовлетворяться R или ![]() .
.
Таким образом, ![]() гарантирует лишь, что система не завершит
работу с “неправильным ответом”, причем не
исключается возможность не завершения работы
при запуске из
гарантирует лишь, что система не завершит
работу с “неправильным ответом”, причем не
исключается возможность не завершения работы
при запуске из ![]() .
.
3. Если конструкция S может иметь
выходом n условий ![]() то
то
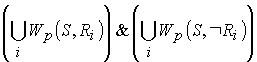
есть описание конечного автомата, представляющего (моделирующего) S.
Воспользовавшись приведенной терминологией, укажем:
предельно вычислимо в частотном смысле, то аппроксимация S может быть построена за конечное число шагов, однако оценка числа шагов невычислима.
Таким образом, возможна реализация конечных программ (структур), моделирующих в частотном смысле нерекурсивные объекты, и существуют две границы сложности формальной конструкции: нижняя граница, при которой поведение конструкции тривиально сводимо к контекстно-свободной модели, верхняя граница - поведение несводимо к конечной модели, но конечно - моделируемо в частотном смысле.
5.5. Информационная устойчивость
Указанные выше условия не содержат указаний, каким образом осуществить их практически при разработке системы и, тем более, при разработке процедур самосовершенствования системы. Ясно лишь, что если сложность формальной конструкции оказывается ниже нижней границы - мы получаем конечный автомат, если выше верхней - конструкцию, диагностика которой потребует перебора всех ее состояний, то есть создания конечно-автоматной модели, заведомо слишком большой, чтобы ее можно было реализовать.
Весьма интересным с практической точки зрения было бы определение некоторых численных, пусть даже имеющих косвенный характер критериев и оценок сложности, пригодных для использования в разработке языков для систем интересующего нас класса.
Рассмотрим процессы, происходящие в некоторой системе высокого уровня. В частности, исследуем акт обращения к системе и акт пополнения информационной базы.
Акт обращения к системе. Пусть
система располагает некоторой информацией,
содержательно представляющей собой некоторое
число М объектов (описаний), связанных N связями и
занимающих некоторое количество бит памяти.
Запрос заключается в указании группы (обычно
одной) из объектов с требованием поиска и выдачи m
объектов и n связей, при этом ответом является
m1 объектов и n1 связей с
ошибкой ![]() и
и ![]() соответственно.
Следующим шагом может быть уточнение запроса,
приводящее к выдаче m2 объектов и n2
связей с ошибкой
соответственно.
Следующим шагом может быть уточнение запроса,
приводящее к выдаче m2 объектов и n2
связей с ошибкой ![]() и
и ![]() и так далее, до
некоторого удовлетворяющего пользователя
значения
и так далее, до
некоторого удовлетворяющего пользователя
значения ![]() . Вообще
говоря, правильно функционирующая система
должна при некотором значении
. Вообще
говоря, правильно функционирующая система
должна при некотором значении ![]() достигнуть некоторой максимальной
точности
достигнуть некоторой максимальной
точности ![]() и при
дальнейших попытках уточнения запроса
оставаться в пределах некоторой допустимой
девиации, что эквивалентно выходу системы на
гомеокинетическое плато.
и при
дальнейших попытках уточнения запроса
оставаться в пределах некоторой допустимой
девиации, что эквивалентно выходу системы на
гомеокинетическое плато.
Интуитивно ясно (практикам знакома
ситуация), что в случае излишне большого числа
связей между объектами уточнение запроса может
приводить к выдаче в качестве ответа все более
широкого класса объектов, не имеющих отношения к
запросу, т.е. к увеличению ![]() .
.
В период ввода в строй уже первых
крупных информационно-справочных систем
разработчики столкнулись со следующим явлением.
По мере накопления информационного банка в
начале случайно, а потом регулярно стала
повторяться одна и та же ситуация. Пользователь,
стараясь получить как можно более точный ответ,
увеличивал число дополнительных (уточняющих)
запросов, но, начиная с некоторого их количества I,
вместо уменьшения ![]() получал все большее число объектов, т.е.
получал все большее число объектов, т.е. ![]() увеличивались (иногда
монотонно, чаще этот процесс был
квазипериодическим от I). Выход из положения
был найден довольно быстро: по выясненным
эмпирически численным критериям было ограничено
число взаимосвязей между элементами базы данных
и указанное явление до некоторой степени
перестало беспокоить пользователей и
разработчиков.
увеличивались (иногда
монотонно, чаще этот процесс был
квазипериодическим от I). Выход из положения
был найден довольно быстро: по выясненным
эмпирически численным критериям было ограничено
число взаимосвязей между элементами базы данных
и указанное явление до некоторой степени
перестало беспокоить пользователей и
разработчиков.
Довольно часто указанное ограничение на число взаимосвязей (точнее говоря, система ограничений) интерпретируется как эмпирическая оценка некоторой объективной “функции ценности информации”. Такая точка зрения широко распространена как в отечественной, так и зарубежной литературе. Отметим, что ее нельзя путать с другим известным и столь же методологически неверным утверждением о возникновении информации только в наборе “человек - контекст – данные”. Последнее утверждение не может быть принято, ибо оно сводит информацию к субъективному существованию вместо того, чтобы рассматривать субъективность оценки информации.
Прикладная теория ИСУ исходит из следующих посылок:
Построим демонстрационную модель динамики информационной структуры системы. Сделаем следующие предположения:
Тогда демонстрационная модель примет вид, представленный на рис.5.1:
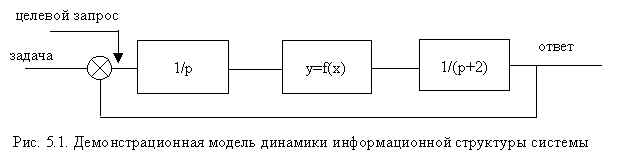
При малых сигналах (эквивалент
“локальных” запросов) система может быть
представлена уравнениями ![]() ; y=f(x).
; y=f(x).
Аналогом коэффициента передачи
нелинейного звена в нашем случае является ![]() , т.е. число связей
данного i-го объекта, где
, т.е. число связей
данного i-го объекта, где ![]() - номер аспекта, по которому
производится поиск.
- номер аспекта, по которому
производится поиск.
Разумеется, такая интерпретация модели допустима лишь в случае независимости аспектов (т.е., в терминологии следящих систем, при отсутствии перекрестных связей между контурами, моделирующими каждый из аспектов).
Качественно полученные значения kmin и kmax для системы, имеющей l аспектов – “координат”, можно интерпретировать следующим образом.
При ![]() min
количество сходных по каждой из “координат”
объектов чересчур мало, что приведет к
“прыжкам” поискового механизма по координатам
ввиду того, что подробности просто отсутствуют.
min
количество сходных по каждой из “координат”
объектов чересчур мало, что приведет к
“прыжкам” поискового механизма по координатам
ввиду того, что подробности просто отсутствуют.
При ![]() max
наоборот, подробностей слишком много, т.е.
поисковый механизм тонет в деталях.
max
наоборот, подробностей слишком много, т.е.
поисковый механизм тонет в деталях.
В более точной постановке необходимо учесть многие упущенные здесь факторы, в частности, взаимосвязь аспектов, неидеальность пользователя как элемента сравнения, более сложную структуру механизмов обработки запросов и организации доступа к базе. Приведенная здесь модель имеет лишь демонстрационный характер. Однако уже сам факт возможности создания модели информационной устойчивости дает нам некоторое обоснование возможности поиска формального инструмента для управления этапом реорганизации информационной базы.
Акт пополнения информационной базы. В этом акте происходит увеличение числа объектов и связей в информационной базе. Проводя пополнение, мы лишь должны следить за устойчивостью системы, причем сделать это можно автоматически на основании принятой модели и известных алгоритмов анализа систем автоматического регулирования.
Постановка задачи автоматизации размещения объектов в информационной базе как задачи исследования устойчивости, по-видимому, является единственно приемлемой, так как позволяет избежать привлечения таких эфемерных понятий, как “функция ценности информации”, “семантическая стоимость” и т.п.
Действительно, априорная информация в каждом акте пополнения, а тем более при проектировании системы, о какой-либо “ценности”, “коррелированности” будущей смысловой начинки просто равна нулю. Отсюда следует закономерный вывод о том, что при начале работ по проектированию мы должны иметь либо универсальную структуру хранения знания, либо использовать стартовый набор информационных записей и стартовую базу знания. Первое невозможно, второе практически невыполнимо. Конечно, и без стартовой информации можно придумать и вычислить соответствующие оценки структур хранения, поставить задачи их “оптимизации”, но какова теоретическая правомочность этих действий хотя бы только с позиций той же задачи устойчивости?
Таким образом, задача устойчивости - единственная формальная модель, применимая в нашей ситуации. Но эта же постановка оказывается и средством для решения проблемы в целом. Изначально можно вообще не задумываться об оптимизации хранения записей. Пусть на некотором шаге пополнения информационной базы нарушаются критерии устойчивости. Означает ли это “закрытие” системы, т.е. невозможность увеличения объема хранимой информации?
Отнюдь нет. Решение достаточно тривиально: создание иерархической структуры, в которой каждый новый уровень может создаваться исходя из своих оценок “функции расстановки” и устойчивости, причем процесс принципиально можно сделать автоматическим по следующей схеме.
Прежде всего на основании уже имеющихся априорных сведений идентифицируются модели основных компонентов, т.е. пользователя, механизма обработки запросов, механизма доступа и т.д.
Далее при пополнении банка решается задача устойчивости для уточненной модели и ограничивается число связей между объектами.
При этом в случае достижения верхней границы числа связей производится автоматическая генерация следующего или следующих уровней иерархии информационного банка, может быть и не имеющих смыслового отделения, но необходимых для обеспечения устойчивости системы.
В предлагаемой модели возможны и более изощренные постановки, уже известные в практике создания систем регулирования, например, задача максимального быстродействия и задачи максимальной чувствительности.
Последние, в частности, приводят к качественно очень интересному решению – к системе, в которой реорганизация связей происходит не только под воздействием акта пополнения информационной базы, но и под воздействием потока запросов. Решение напрашивается по аналогии с системами управления, использующими шумовые компоненты входного сигнала для поддержания коэффициента усиления на грани устойчивости.
| Site of Information
Technologies Designed by inftech@webservis.ru. |
|