СИСТЕМА ПОИСКА В СЕТИ
INTERNET НА БАЗЕ ИСПОЛЬЗОВАНИЯ НЕЙРОННЫХ СЕТЕЙА.Э. Рахматулин
Ульяновский государственный технический университет
Abstract — The paper shows application of neural networks for organizations of search in the Internet. Search system structure and methods to its realization are described. Principles of permission of search’ s system are discussed. Application of neural network as heteroassociation memory is offered. The research is devoted modification Hamming’s neural network with the purpose of search both on key words, and on their synonyms.
В рамках быстрорастущей и динамично изменяющейся сети
Internet доступны самые разнообразные информационные ресурсы. Для ориентации в этом море информации, к наст оящему времени создано огромное множество поисковых средств - от поисковиков внутри сайтов до поисковых систем, содержащих ссылки на миллионы адресов. Но зачастую такие средства не удовлетворяют по ряду причин многих пользователей (например, даже при гра мотном составлении запросов часто невозможно выделить необходимую информацию из множества предложений). В этой связи было предложено применить средства мягких вычислений, а именно нейронных сетей (НС), в поисковой сист еме.Схема такой системы приведена на рис.1
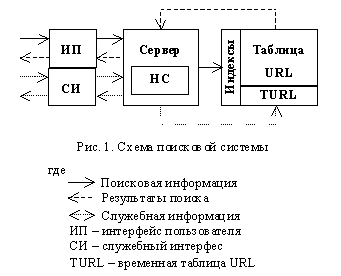
В такой схеме НС функционирует в двух качествах: как средство выбора информации из баз данных и как средство для внесения новой информации в соответствующие базы данных. Это становится возможным в результа те обучения нейронной сети словарю ключевых слов, содержащихся в документах, по которым производится поиск.
НС реализована в виде эмуляции на персональном компьютере нейронной сети Хемминга. Число нейронов выходного слоя такой сети определяется числом хранимых ей ключевых слов. Выходы НС определяется вектором значений снимаемых с аксонов не йронов выходного слоя. Но реально используется только номер нейрона с максимальным значением выхода. Данный эмулятор поддерживает изменение нейронов выходного слоя, а также изменение входных узлов, что используется при добавлении и удалении документов в поисковую систему.
В качестве одного из вариантов представления обучающей выборки можно предложить такой, когда обучающая выборка состоит из набора ключевых слов, которые будут преобразованы эмулятором НС в бинарные векторы. Такой подход дает возможность получать на выходах НС номер (по номеру активизировавшегося нейрона выходного слоя) индекса, к которому принадлежит поданное на входной слой НС слово.
Функционирование НС в процессе поиска URL по ключевым словам сводится к определению номеров индексных таблиц, в которых хранятся ссылки на основную базу URL, содержащих ключевое слово. Далее вступают в действие традиционные алгоритмы по выборке и выводу конечному пользователю результатов
поиска. Сходным образом НС используется и для внесения новых URL в базу данных. В этом случае с помощью традиционных алгоритмов забирается информация по рассматрив аемому адресу и разбивается на отдельные слова, находятся неизвестные образцы, среди которых отсекаются стоп - слова, и на оставшихся образцах производится дообучение нейронной сети и создаются необходимые индексы. З атем разобранный на слова документ анализируется НС, в результате чего формируется массив номеров индексных таблиц, в которые, после занесения в основную БД URL информации о новой URL, добавляется ссылка на соответствующую запись БД URL.Предлагаемая поисковая система функционирует следующим образом.
Запрос принятый с помощью ИП разделяется сервером на отдельные слова, которые последовательно подаются на входы НС, затем, получив номера индексов с выходов НС, сервер производит операцию пересечения над полученными множествами. Резуль тат этой операции и является результатом поиска.
В качестве средства хранения БД был выбран СУБД
Oracle 7.3.3. Такой выбор был сделан по ряду причин: высокая производительность СУБД, обеспечение секретности, удобство проектирования сложных БД, а т ак же доступность данного продукта. Как видно на рис.1 БД состоит из 3-х основных видов таблиц: множество таблиц индексов, таблица Internet адресов (URL), и таблица временных Internet адресов (TURL). Таблицы индексов включают в себя следующие поля: <Приоритет>, <ссылка на URL>, <Восстановленный текст>. Поле <приоритет> показывает приоритет ключевого слова, представляемого этой индексной таблицей, в данном документе, поле <ссылка на URL> ука зывает на строку таблицы URL, поле <восстановленный текст> содержит ту часть исходного документа, где содержится данное ключевое слово. Количество таких таблиц определяется количеством ключевых слов, по которым п роизводится поиск.Таблица
URL состоит из 2-х полей: поля <Номер> и <Адрес>. Поле <номер> является уникальным номером документа и служит для связи индексных таблиц с таблицей URL. Поле <адрес> содержит Internet адрес данного документа.Таблица
TURL предназначена для включения новых документов в систему поиска и имеет ту же структуру, что и таблица URL.Интерфейс пользователя и служебный интерфейс реализован в форме
CGI- скриптов. Служебный интерфейс предназначен для удаленного администрирования поисковой системы, а такж е для внесения новых адресов в БД.В дальнейшем планируется модифицировать НС Хемминга с целью обучения НС не ключевым словам, а группам синонимов.
Литература
| Site of Information
Technologies Designed by inftech@webservis.ru. |
|